Beyond AI Governance: AI Control Systems

TL;DR
- AI governance is inherited from deterministic software. Applying it to complex, self-learning AI systems is a category error.
- The right frame is control theory: continuous sensing, feedback loops, and domain-specific actuators - not one-time certification.
- Different AI systems need different control architectures. A drug discovery model and a medical diagnostic model are not the same control problem.
- Building this discipline requires developing sensors, actuators, and control algorithms we do not yet fully have - and learning from large-scale experimentation across millions of deployments.
- Unlike aircraft, we can run these experiments at 1000x speed. The scale is the opportunity.
We are Making a Category Error
Every major AI governance framework today is built on the same core concepts: auditability, admissibility, constraints, preconditions. They reflect a genuine attempt to bring AI within the scope of existing accountability infrastructure including regulatory accountability.
The problem is these governance approaches were designed for traditional software, which is deterministic. The behavior was readable from code, software is stable, and usage provides consistent answers. Certification means something stable, because the thing being certified does not change after you certify it. These assumptions are so deeply embedded in governance thinking that most frameworks never even state them. They just build on them.
Modern AI systems violate every one. They are non-deterministic, open-ended, and self-learning. A medical diagnostic model whose recommendations shift as it ingests new clinical data. A drug discovery system deliberately engineered to venture beyond known chemical space. A tutoring application that continuously adapts to each learner and is supposed to drift. An autonomous robot operating in physical environments where a control failure has immediate real-world consequences. A financial risk model whose admissibility is scrutinized by regulators who want proof that the oversight loop itself is functioning. All these systems have different control problems. One governance framework trying to cover all of them.
The system you certified yesterday is not the system running today. Applying static governance concepts to dynamic systems does not fail loudly. It fails silently, producing documentation that looks like oversight while the actual behavior of the system drifts well past anything the audit captured.
This is a category error. And the fix is not more old-style governance.
What We Actually Need: A Control System
I want to be clear about what I mean by an AI control system, because the term gets used loosely. It is not a replacement for governance. It is a technical and institutional architecture that treats AI oversight as a continuous engineering problem rather than a one-time certification event. It has four components:
- Sensors: instrumentation that monitors system behavior and drift in deployment
- Control algorithm: a method for deciding whether the system needs correction and what kind
- Actuators: mechanisms to intervene, such as fine-tuning, deployment constraints, or policy updates
- Feedback loop: continuous, operating at timescales matched to how fast the system actually changes
Within this architecture, the old concepts find their proper home. Auditability becomes a property of the sensor infrastructure, not a snapshot taken once. Admissibility standards get applied to a system tracked over time. Preconditions get enforced dynamically, not verified at the gate and then forgotten. Everything gets reoriented around the actual dynamics of what we are trying to govern.
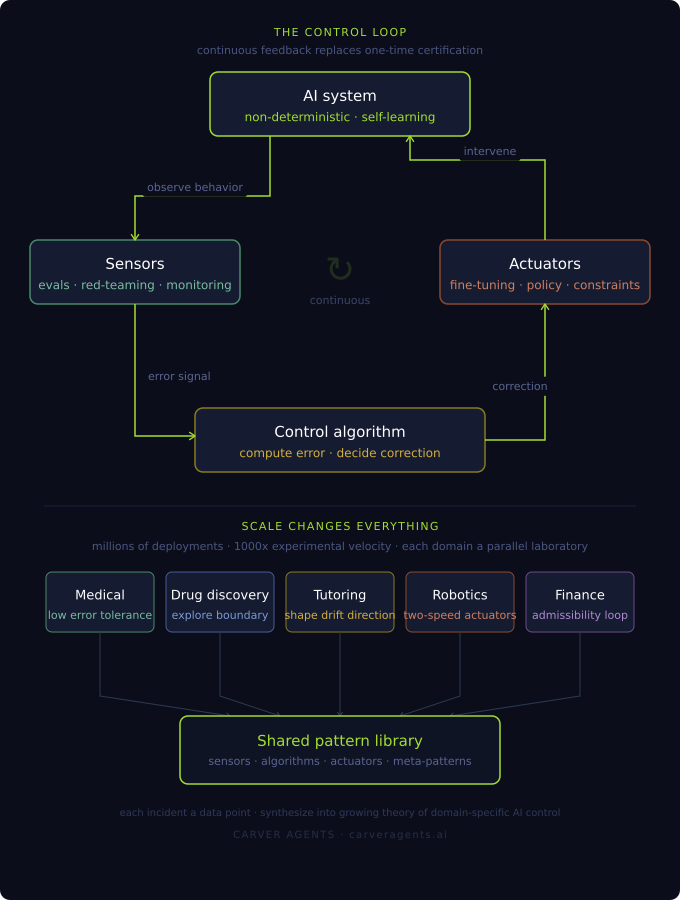
Need for Multiple Control Architectures
AI gets treated as a single category, as if the principles governing a medical diagnostic model should govern a drug discovery system, a tutoring application, or an autonomous robot. These are not the same class of dynamical system. Four dimensions shape the control architecture you actually need:
- Tolerable error rate: how much deviation before intervention is required?
- Feedback latency: how quickly can you detect and correct drift?
- Exploration objective: should the system converge on a known operating point, or push into novel territory?
- Consequence severity: what does a control failure actually cost?
Assessment of various scenarios:
MEDICAL DIAGNOSTIC AI: Low error tolerance, hard auditability requirements, outputs subject to clinical and legal admissibility standards, conservative corrections, preconditions on training data provenance are not optional.
DRUG DISCOVERY AI: Deliberately exploratory. The whole point is productive deviation from known chemical space. A controller that suppresses novelty-seeking behavior here is not keeping the system safe. Constraints belong at the boundary, not throughout the interior.
TUTORING AI: Adaptation is the feature. Drift relative to a fixed baseline is expected and often desirable. The control problem is shaping the direction of drift, not eliminating it.
AUTONOMOUS ROBOTICS: Physical-world consequences require two-speed actuators. Millisecond-level safety intervention runs in parallel with slower governance-level policy correction.
FINANCIAL RISK AI: Operates under explicit regulatory admissibility requirements. The control problem includes a meta-layer: not just demonstrating that outputs are acceptable, but demonstrating to regulators that the feedback loop monitoring those outputs is itself functioning.
The approach can be universal. The engineering of those approaches into operational systems is necessarily domain-specific.
Developing a Discipline of AI Control Systems
Control engineering did not rediscover feedback theory for every new aircraft model. It built reusable design patterns and tuned them per context. The PID controller works across wildly different physical systems because the pattern is general even when the constants and constraints are specific. That is what made the discipline cumulative rather than perpetually starting over.
We need the same for AI governance. Not a single universal framework, but a library of composable patterns:
- Multi-timescale feedback: layering real-time monitoring over weekly behavioral testing over quarterly policy review, matched to how fast each system class actually drifts
- Constrained exploration: control designs for systems where productive deviation is the goal, with hard boundaries at the edge rather than throughout
- Audit-trail-as-sensor: infrastructure that makes continuous logging actionable in real time, not just available for retrospective review after something goes wrong
- Multi-objective reconciliation: methods for when safety, capability, and admissibility constraints pull in different directions, which they routinely do
This library does not yet exist in consolidated form. Pieces of it are being assembled by safety researchers, red-teamers, regulatory technologists, and domain specialists who mostly do not know they are working on the same underlying problem. What is missing is the recognition that this is a shared engineering discipline with intellectual lineage, reusable methods, and the expectation of cumulative progress.
The scale of deployment actually helps here, but it also raises the stakes considerably. We are not talking about a few hundred regulated systems that compliance teams can review manually. We are heading toward a world of billions of AI agents, each evolving, each operating in a different context, each potentially subject to different regulatory regimes across jurisdictions. Manual compliance review at that scale is not just slow. It is simply not possible.
Path Forward
AI systems are not waiting for governance to catch up. They are deployed, learning, and drifting on healthcare decisions, financial risk models, educational platforms, and hiring pipelines right now, while governance frameworks are still being debated in working groups. The velocity mismatch is not a temporary problem. It is the permanent condition we are designing for.
Here is the difference that matters. When aircraft engineers built the first control systems, each experiment was expensive, slow, and singular. A prototype took years and hundreds of people. You learned from one system at a time. That constraint shaped the entire discipline - cautious, theoretical, heavily model-driven before any hardware flew.
We do not have that constraint. We have millions of AI deployments running simultaneously, across every domain, generating failure signals and behavioral data at a velocity classical engineering never experienced. We can run the equivalent of a thousand years of aircraft control experiments in a single year. Every deployed system is an experiment. Every incident is a data point. Every domain - medical, financial, educational, robotic - is a parallel laboratory.
What we need is the infrastructure to treat it that way. Not to let each failure be a surprise and each governance response be invented from scratch, but to synthesize what we are learning into a growing, shared theory of domain-specific AI control systems. Shared behavioral data. Meta-level patterns that generalize across domains. Models that learn what good control looks like from the aggregate of millions of deployments.
This is what the Programmatic AI Compliance initiative is building toward. Not a compliance checklist at scale, but the instrumentation, pattern libraries, and learning infrastructure that turns the scale of deployment into a scientific and engineering asset. DM if you want to learn more or join the effort.